
お久しぶりです。shimesaba_oishiです。
最近急に寒くなりましたね。。秋を返してほしいと思う今日この頃です。
最近SASの勉強をしているのですが、業務ではあまり意識していない「DATAステップ処理の裏側」についてご紹介しようと思います。
前回の記事はこちら👇
1.各フェーズについて
まずSAS DATAステップは2つのフェーズで処理されています。まずは各フェーズの名前とざっくりとした処理をみていきましょう。
- コンパイル・フェーズ
- 入力バッファとプログラム・データベクトルの作成
-
各ステートメントの構文エラーを確認
- 実行フェーズ
- DATAステップによる入力データの読み込み
- データセットの出力
処理フローはこんな感じです。↓
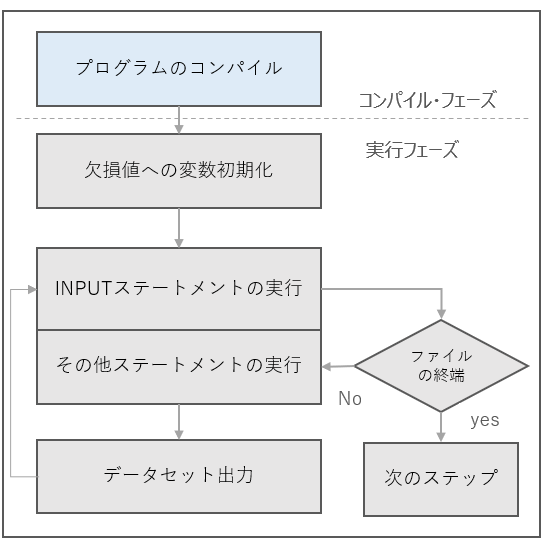
次に各フェーズについて何をしているのかもう少し詳しくみていきます。
2.コンパイル・フェーズ
入力バッファ
まず入力バッファと呼ばれるメモリ領域が作成されます。ここには外部ファイルからのレコードが保持されます。
プログラム・データベクトル
これはSASが一度に1オブザベーションを保持するメモリ領域です。ここには2つの自動変数が含まれています。
- _N_:DATAステップが実行を始める回数
- _ERROR_:実行中に起こるエラーの回数

構文チェック
キーワードの欠落やスペルミス、無効な変数名やオプションなどといった、構文エラーを検知します。
変数の追加
INPUTステートメントのコンパイル時の、各変数に対する領域が先ほどのプログラム・データベクトルへ追加されます。
ディスクリプタ部の作成
最後にデータセットのディスクリプタ部を作成していきます。ここにはデータセットの名前や変数の数、変数の名前や属性の情報が含まれます。
このようにコンパイル・フェーズではまず入力データを読み込み、データセットへ出力するための準備を整えているのが分かります。
3.実行フェーズ
コンパイル・フェーズが完了したら次は実行フェーズへうつります。このフェーズでようやくデータの読み込み・出力が実行されます。
ここでは例として、左から「管理番号」,「名前」,「年齢」,「性別」,「体重」,「身長」の情報を持つデータ(testdata)を用いてお話していきます。

データ(testdata)を読み込んでデータセットを出力します。


この時の実行フェーズにおける処理の裏側を見ていきましょう。
変数の初期化
実行フェーズ開始時は下記自動変数が以下となります。
- _N_:1
- _ERROR_:0

INFILEステートメント
生データファイルの場所を識別します。
INPUTステートメント
コンパイル・フェーズ時に作成された入力バッファに最初の1レコードを読み込みます。各カラムのデータが順にコンパイル・フェーズ時に作成されたプログラム・データベクトルに割り当てられます。

DATAステップの最後
以下の処理が行われます。
- プログラム・データベクトルの値が最初のオブザベーションとして出力される。

- DATAステップの最初に戻り次のレコードを読み込む準備を行う。(_N_は2となる)
- プログラム・データベクトルの変数値が欠損に再設定される。

DATAステップの繰り返し
次のレコードが入力バッファに読み込まれ、プログラム・データベクトルに割り当てられます。そしてそのデータをデータセットに出力。これを繰り返し、ファイルの終端まで来たらDATAステップは終了です。
4.おわりに
いかかでしたでしょうか。今回は「DATAステップの処理の裏側」についてお話しました。普段あまり意識しづらい部分ではありますが、処理の流れを理解できればその知識をエラーの検知や修正に利用できる場面が増えると思います。
ここまでご覧くださり、ありがとうございました!
さらに詳しい資料はこちらから。
データ分析の必要性から、CSSが取り組んできたデータ分析の実績や事例までをまとめてご説明します。
